EPL ML Model
· 2024Group ML project comparing models for Premier League match prediction across a long historical dataset.
A group study on predicting English Premier League match outcomes from more than 20 years of historical data. We cleaned the dataset, engineered features, and compared eight models under the same evaluation setup to see what actually held up.
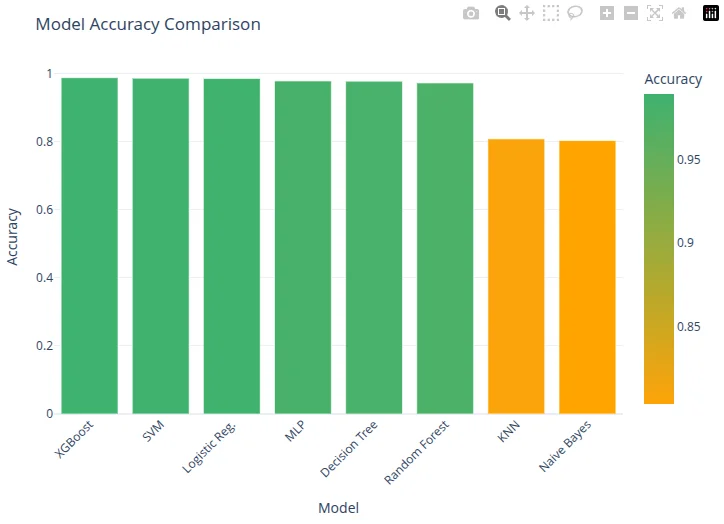
- 01 Compared Random Forest, MLP, Decision Tree, KNN, Naive Bayes, Logistic Regression, XGBoost, and SVM.
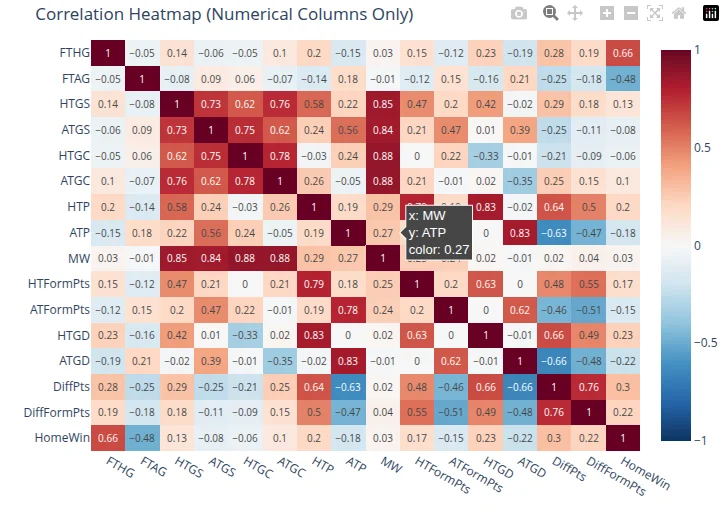
- 02 Feature set included 39 match-level inputs after handling missing values, outliers, and engineered form signals.
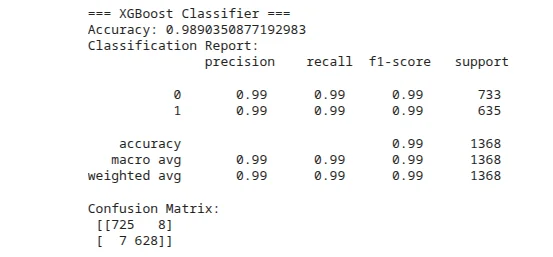
- 03 XGBoost produced the strongest documented result in the final comparison.
- 04 The project reinforced that data cleaning and feature design mattered more than endlessly swapping model classes.